

Kennis maakt stennis
De berg aan wetenschappelijke kennis groeit voortdurend, voornamelijk in de vorm van online artikelen op papierformaat. Een zoektocht naar nieuwe manieren voor het opslaan en verspreiden van kennis leidde tot een gesprek met Alex Brandsen over 'knowledge graphs'.
Het gebeurt alweer. Je geeft je beste argument om er eindelijk klaar mee te zijn, maar dan hoor je het antwoord: "Nope, niet waar! Het is meer als x,y,z..." Hoe kan dat nou, nog een meningsverschil? Waarom is het dan niet waar? Daar gaan jullie weer, verder inzoomend op de details van het oorspronkelijke onderwerp, zonder een expert op het gebied zijn.
Hoe handig zou het zijn als je zo’n zijspoor met één online zoekopdracht de kop in kon drukken? Om vervolgens de - vaak interessantere - discussie weer door te zetten. De discussie waarin je verkent wat het onderliggende probleem is, of wat jullie kernwaarden eigenlijk zijn.
De berg aan (online) wetenschappelijke kennis waar we allemaal zo ijverig aan proberen toe te voegen groeit voortdurend. Toch verbeteren we nauwelijks de manier waarmop we onze resultaten organiseren, delen en bespreken. In plaats van het publiceren van statische teksten in papierformaat, zouden we een manier kunnen ontwikkelen om data op een gebruiksvriendelijke, openlijk beschikbare, en visuele manier op te slaan. En dat op zijn eigen wetenschappelijk verantwoorde en betrouwbare platform.
Zo'n platform voor 'wetenschappelijke consensus' zou op de een of andere manier kennis moeten kunnen samenvatten en opslaan, en allerlei bestaande wetenschappelijke literatuur moeten bevatten voor de geloofwaardigheid. En dit alles gecombineerd in een soort Redditachtig discussieforum. Klinkt vergezocht?

Graven naar bestaande kennis
Ik sprak met Alex Brandsen, postdoc onderzoeker Digitale Archeologie aan de Universiteit Leiden, om dit idee te onderzoeken. "In de Archeologische literatuur creëren we enorme hoeveelheden obscure gegevens die in wetenschappelijke publicaties worden gepubliceerd", legde Brandsen het probleem uit waaraan hij werkt. "De metadata (beschrijvingen, red.) van publicaties bevatten meestal niet genoeg informatie om te zien wat er daadwerkelijk in staat. We hebben text mining en machine learning gebruikt om deze verborgen kennis te kunnen vinden en organiseren." Eigenlijk dus een digitale vorm van graven naar het onbekende, net als ‘echte’ archeologie.
"Je kunt bijvoorbeeld een bepaald opgegraven ding hebben, laten we zeggen de Limburgse gele pot A. Die wordt dan op allerlei manieren beschreven en nuttige feiten erover worden afgewisseld met minder relevante informatie in hele lange zinnen. Om entiteiten als deze pot automatisch uit tekst te kunnen halen met behulp van een machine learning model, moet je het trainen met duizenden voorbeelden van de verschillende namen die voor dit soort objecten worden gebruikt."
Het voltooide model werd vervolgens omgezet in een zoeksysteem met de naam AGNES, dat kon worden losgelaten op de wetenschappelijke literatuur in een archief. "We voerden een casestudy uit waarin we keken naar vroegmiddeleeuwse crematies. In deze studie vonden we 30% meer crematies dan momenteel bekend is bij deskundigen op het gebied."

"Dit laat zien dat we met dit soort technologie al bestaande gegevens echt toegankelijker en waardevoller kunnen maken." In hun huidige onderzoeksproject EXALT ontwikkelen Brandsen en de rest van zijn team het AGNES-zoeksysteem tot een echt functionerende zoekmachine voor archeologisch onderzoek.
Om zoiets als EXALT te creëren voor de hele wetenschap, hebben we ook een manier nodig om enorme hoeveelheden gegevens op te slaan. De huidige FAIR-data beweging wil gegevens vindbaar, toegankelijk, interoperabel en herbruikbaar maken, zegt Brandsen: "Met FAIR wordt vooral gesproken over manieren om gegevens op te slaan zodat ze over 10 jaar bruikbaar zijn. Momenteel staat er data uit de jaren 80 op een floppydisk die niet toegankelijk is omdat de computer die het kan lezen gewoon niet meer bestaat. Dat wil je voortaan voorkomen door goede dataopslagmethoden te gebruiken."
Kennis opslaan
Dat kan op allerlei manieren, aldus Brandsen: "Als iemand, laten we zeggen professor X, een kikker ontdekt, moet je die concepten en de relaties daartussen vastleggen. Wij gebruikten een meer traditionele methode die XML heet, maar een knowledge graph (KG) maken kan ook. In zo’n knowledge graph is het concept 'professor X' een object dat je kunt koppelen aan andere objecten, zoals zijn universiteit en de pas ontdekte kikker."
Ook al is dit een heel simpel voorbeeld van een knowledge graph, kun je je voorstellen hoe groot en complex de dataset zou moeten zijn om alle kennis te omvatten. Brandsen legt het dilemma uit: "Hoe meer complexiteit je toevoegt aan de knowledge graph, hoe moeilijker hij te maken is. En hoe simpeler je hem maakt, hoe minder bruikbaar hij is. Maar dit is misschien één van die dingen die nu onmogelijk lijkt, maar er over tien jaar een of andere techgigant een hoop geld en rekenkracht tegenaan heeft gegooid om het voor elkaar te krijgen."
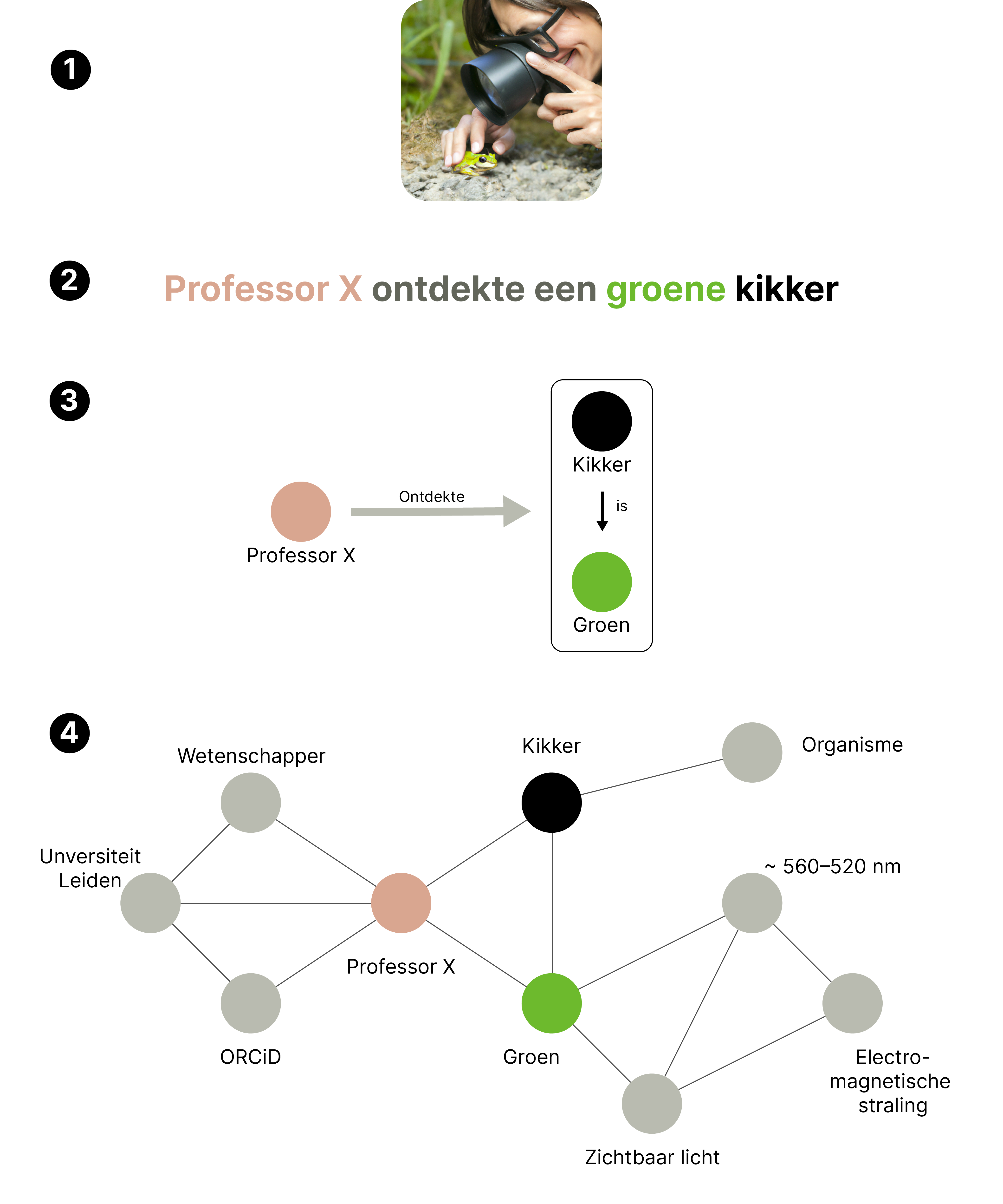
(1) Een wetenschapper bekijkt een groene kikker. (2) Tekstuele beschrijving van wat er gebeurt met concepten in kleurcode. (3) Abstractere versie waarin concepten als ‘objecten’ zijn weergegeven, met relaties daartussen in pijlen. (4) Weergave hoe deze simpele gebeurtenis met een paar toevoegingen al een zeer complex web kan worden.
De weg ernaar toe
Huidige zoekmachines zoals Wolfram Alpha of de Open Research Knowledge Graph zijn nog niet doorgedrongen tot het grote publiek. Naast dat ze nog in ontwikkeling zijn, zou het ook kunnen dat deze teveel lijken op een logge wetenschappelijke database, en te weinig op een moderne, intuïtieve app die iedereen begrijpt. Om nuttig te zijn voor iedereen, moet het bruikbaar zijn voor iedereen.
Je zou ervoor kunnen pleiten om van het platform een soort van sociaal medium te maken, waarin wetenschappelijke discussie wordt gedeeld met het publiek. Zo zou iedereen gegevens kunnen bijdragen aan de knowledge graph, zolang ze maar geldige argumenten gebruiken. Klinkt perfect, totdat je nog eens nadenkt over hoe dat uitpakte bij bijvoorbeeld Twitter. De kwestie van geloofwaardigheid, dus of wetenschappers en gebruikers zo'n platform en de inhoud zullen vertrouwen, hangt sterk af van de manier waarop het is gemaakt.
Brandsen waarschuwt dat het onverstandig kan zijn om dit in handen te laten van particuliere bedrijven als Microsoft of Google. "Wanneer zij iets als Google Scholar creëren, is het mechanisme erachter vaak niet openbaar. Je kunt dus niet zien hoe ze met informatie omgaan, en of er misschien een vooroordeel in hun methode zit." Amazons sollicitatie-AI bijvoorbeeld, die vrouwen discrimineerde omdat hij was getraind met gegevens van het voornamelijk mannelijke personeel van Amazon.
Dit soort ethische problemen moeten worden voorkomen door de onderliggende mechanismen voortdurend onder de loep te nemen. Anders kan het kennisplatform veranderen in een wapen van onderdrukking in plaats van een instrument voor vooruitgang.
Aangezien de motivatie van Big Tech bedrijven vooral bestaat uit geld verdienen, zal de drijvende kracht achter de oprichting en regulering van het platform het liefst vanuit de overheid of de wetenschap zelf moeten komen. Een interessant voorbeeld hiervan is The Underlay, een spin-off van het Massachusetts Institute of Technology. Ook zullen sommigen pleiten voor een meer ‘gedecentraliseerde’ oplossing zoals web3 of blockchain, zoals de laatste tijd wel vaker gebeurd.
Brandsen verzucht: "Veel technologieën zijn onvoorspelbaar en groeien exponentieel, waardoor je heel optimistisch zou kunnen zijn dat zoiets mogelijk is. Maar om het goed te maken heb je enorme hoeveelheden manuren, geld en goodwill nodig van onderzoeksinstellingen, universiteiten en alle andere belanghebbenden. Dat is het moeilijke deel."

We kunnen inmiddels alle informatie opzoeken die we willen, maar daardoor is het probleem wellicht verschoven van het vinden van kennis naar het filteren van kennis. Ooit gehoord van confirmation bias, onze neiging om vooral de feiten te onthouden die onze al bestaande meningen ondersteunen? De aanwezigheid van alle informatie is nodig, maar niet genoeg voor goede besluitvorming.
Dit soort technologieën zijn dus slechts hulpmiddelen en niet de oplossingen voor onze sociale problemen. Daarom moet de meerderheid van onze discussies draaien om het vinden van onze kernwaarden en die vervolgens zoveel als we willen op één lijn te brengen. Als we dat gedaan hebben, hebben we manieren nodig om door onze kennis te ziften en die slim in te zetten. Google helpt niet erg mee. Dus hoe gaan we dit in de toekomst aanpakken?
Alle afbeeldingen zijn gemaakt door een AI, met DALL-E (https://labs.openai.com/). Nice he!



0 Reacties
Geef een reactie